Health Data Re-Identification Risk
A New Zealand Primary Care Perspective
Health data is routinely used for statisical and research purposes in d-identified form sin New Zealand. The New Zealand Health Information Privacy Code allows the use of health information for research or statistical purposes as long as the information will not be published in a forma that can be reasonably used to identify individuals.
So what does need to be done in order to ensure that data can’t be re-identified?
We took routinely collected administrative data for 434,844 people and generated random groupings of 1,000, 5,000, 10,000, 40,000, 150,000 250,000 and 434,000 individuals. We used nine demographic descriptors (quasi-identifiers), grouped in six various ways to emulate their use in real world situations (quasi-identifier models).
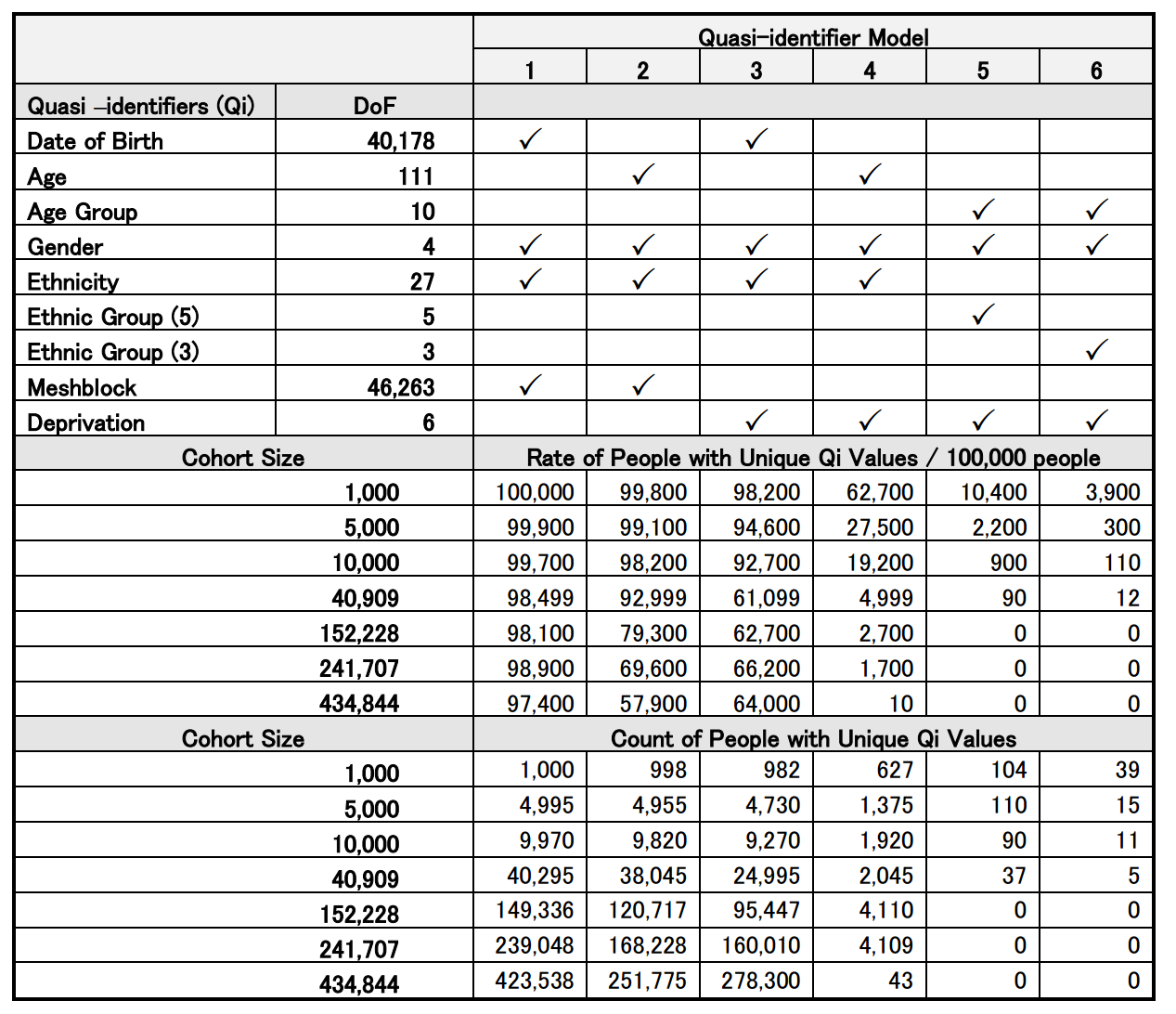
We identified in each cohort size the number of individuals with unique combinations of demographic variables. We assessed a model as having low risk for re-identification where there were no individuals with unique demographic variables. This is however a relatively low threshold given that in s sample of 150,000 individuals if any individual shares demographic characteristics identical to only one other person, we considered the re-identification risk to be low ( termed k-anonymous = 1 ).
We concluded that care must be taken when using data sets below 150,000 individuals. Any such data sets should not publish data by small area census units (meshblock) and shoudl have age and ethnicity information aggregated.
MacRae J, Dobbie S, Ranchod D. Assessing Re-identification Risk of De-identified Health Data in New Zealand. Health Care and Informatics Review Online, 2012, 16(2), 24-30.
Our Role
DataCraft’s Chief Scientist, Jayden MacRae was the lead author on this paper and undertook the study design, and writing.